- Accueil
- Tous les articles
- Par catégorie
- Les plus récents
- Hacking 101
- Blog
- Vers le vrai hacking
- Sources exemples

Les bases de l'exploitation Web
| Inclusions dynamiques >> |
Puisque la base de tout en sécurité est la compréhension, commençons par le commencement :
comment est-ce que ça marche ? En d'autres termes, lorsque je prends mon navigateur et que je demande
l'URL http://www.bases-hacking.org/, quels sont les acteurs et les moyens de communication permettant la
bonne navigation et l'affichage des différentes ressources ? Voici ce à quoi nous allons tenter de répondre
brièvement dans ce premier article.
Communication et résolution DNS
Première étape, la résolution DNS (Domain Name System). En effet, il est bien joli de vouloir contacter www.bases-hacking.org, mais l'ordinateur ne sait pas plus que vous où le trouver. Ceci nous ammène à considérer les fondements de l'Internet. Comment les ordinateurs communiquent-ils entre eux ?
On peut voir l'Internet comme une sorte de toile d'araignée géante (d'où le www, World Wide Web) constituée de noeuds que sont les routeurs et autres équipements télécom permettant la transmission des messages. Le schéma suivant donne une vision très schématique de ce qu'est l'Internet et permet d'envisager la façon dont peuvent communniquer différents acteurs.
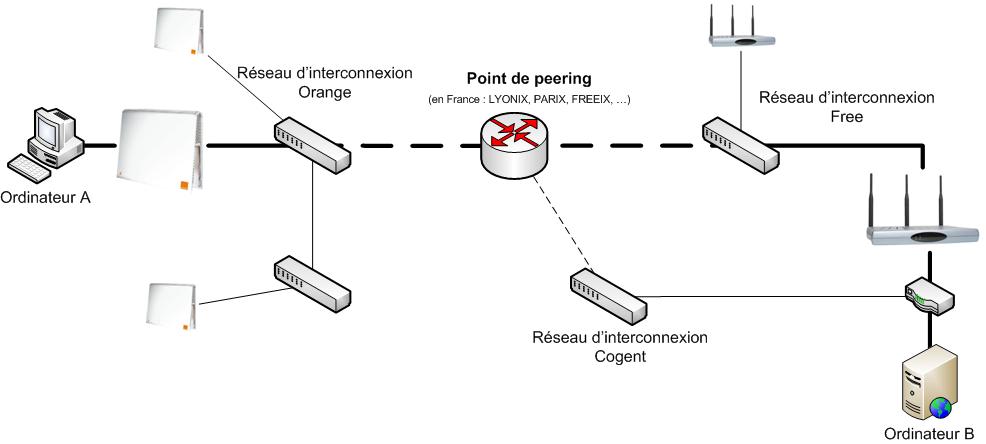
Dans cet exemple, nous avons l'ordinateur A ayant par exemple comme fournisseur d'accès Orange et cherchant à joindre l'ordinateur B qui a deux connexions, l'une chez Free et l'autre chez Cogent. Tout d'abord, le message de A va devoir sortir de son réseau local (via un routeur ou autres modems ADSL). Une fois sorti, il se retrouve sur le réseau de son ISP (Internet Service Provider, Fournisseur d'Accès Internet ou FAI en français). Le message va être routé (ie, transporté) vers ceux que l'on dénomme les "points de peering", autrement dit de gros switchs où viennent s'interconnecter les ISP ainsi que certains professionels, notamment les hébergeurs. Le message passe donc dans le réseau de Free ou dans celui de Cogent pour arriver vers l'ordinateur B, en passant par les réseaux internes de l'ISP concerné, de la même façon qu'à l'aller.
Les messages transitants de cette façon utilisent un protocole de communication appellé IP (Internet Protocol), qui assigne à chaque noeud du réseau une "adresse" numérique composés de quatres octets (entre 0 et 255), bien connue sous le nom d'adresse IP. Ainsi, si tous les composants du réseau sont correctement configurés, ils vont tout simplement pouvoir faire transiter les paquets vers la cible correcte. Par exemple, on pourrait configuer un routeur en lui indiquant que tous les messages en direction de 1.2.3.4 doivent passer par Cogent, ceux qui sont de type 1.4.3.5 sont utilisés par Free, etc... Ces règles sont aussi appellées routes. Aller plus en profondeur sur les moyens de communication mis en oeuvre serait fort intéressant mais n'est pas notre but ici. Nous voulons simplement donner une idée grossière de la façon dont les communications s'effectuent.
Le dernier maillon de la chaîne est donc ce fameux DNS. En effet, il existe des registres permettant d'associer des noms de domaines (ici, bases-hacking.org) avec les adresses IP que nous venons d'évoquer. En réalité, l'ordinateur A va demander à son serveur DNS préféré l'adresse du nom demandé. Ce serveur intermédiaire va consulter ceux que l'on nomme les root servers, qui sont au nombre de 13 et constituent la base de l'Internet actuel. Ils vont consulter leur registres. S'ils ne connaissent pas le nom, ils vont rediriger vers un autre serveur DNS responsable de la zone en question (par exemple, les .org sont maintenus par les serveurs X.Y.Z.D et Z.E.R.D). Si ces nouveaux serveurs ne connaissent pas le nom, ils vont encore déléguer au serveur DNS responsable de la zone en question, etc, jusqu'à ce que le nom soit trouvé ou qu'un serveur n'ai ni le nom en base, ni un serveur auxiliaire responsable d'une zone liée au nom de domaine. Une fois cet enchaînement terminé, le serveur préféré va pouvoir retourner la réponse au demandeur, comme dans l'exemple qui suit :
Avec tout cela, notre navigateur a enfin déterminé qui nous souhaitons qu'il contacte. Puisque rien n'est superflu dans l'URL que nous avons entrée, c'est que ce http:// doit servir à quelquechose, non ? En effet, comme nous allons le voir tout de suite, ce préfixe indique le protocole, ou langage, qui va être utilisé entre nous et bases-hacking.org pour que chacun puisse comprendre les questions/réponses de l'autre.
De l'autre côté de la barrière se trouve donc le serveur Web (Apache, IIS, JBoss, GlassFish, etc...), ou serveur HTTP (HyperText Transfert Protocol). Le protocole HTTP est donc finalement le langage qui va permettre au client (le navigateur) de demander au serveur des ressources (par exemple, vous avez demandé ici au serveur la ressource fonctionnement-web.html). Ensuite, le serveur, connaissant la demande, est libre de chercher la ressource, en ajoutant des données dynamiques ou non et la renvoie via ce même protocole au client. On parle donc de requêtes (du navigateur) et de réponses (du serveur) HTTP. Requêtes et réponses sont toutes formées de la même façon : des en-têtes, ou headers décrivent la demande et fournissent des indications supplémentaires (permettant d'identifier le client, son navigateur, le type de langue qu'il sait lire ou encore des informations sur les données à suivre par exemple). Ensuite suivent les données à transmettre. Un petit aparté sur les headers HTTP et le protocole en général est fait dans un article annexe, ne nous attardons donc pas plus sur ce langage et revenons à notre serveur.
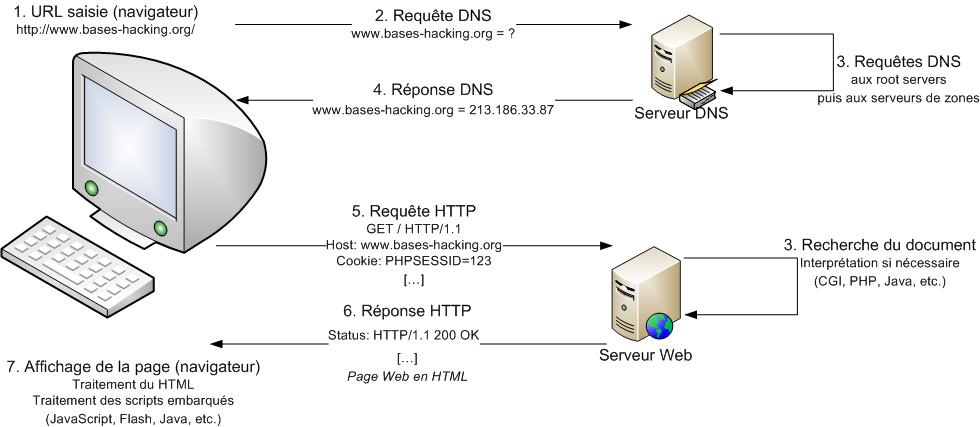
En effet, côté serveur, on est libre de faire les traitements internes nécessaires afin de rendre un résultat personnalisé à l'internaute. En réalité, les fichiers distants demandés peuvent être écrits avec n'importe quel langage de programmation (de façon plus commune, PHP, ASP, Java, PERL...). Le serveur va les analyser et les exécuter avant d'en renvoyer les résultat. Le serveur possède donc ou peut contacter diverses resources, bases de données ou programme d'interprétation qui vont garantir au client distant une navigation plus évoluée. Ainsi, une requête HTTP vers www.bases-hacking.org pourrait être schématisée de la manière suivante :
De son côté, le navigateur va recevoir les données et les mettre en forme de manière visuelle pour les rendre à l'utilisateur. De manière générale, le contenu Web est formatté selon le langage HTML (HyperText Markup Language). Par exemple, vous pouvez faire clic droit > Afficher la source pour voir le langage dans son plus simple appareil. Plusieurs types de contenus/langages (images, Java, JavaScript, Flash, etc...) peuvent être incorporés à ce HTML et seront analysés et affichés par le navigateur. Des parties de ces données peuvent également être stockées sur l'ordinateur de la personne qui consulte le site, afin d'enregistrer des profils de navigation ou un identifiant réutilisable pour une authentification ultérieur. Ce sont les cookies (article annexe).
Voici donc pour les basiques du fonctionnement de l'Internet et plus particulièrement de la navigation sur les sites Webs. Passons donc sans plus attendre à nos premières exploitation : les inclusions dynamiques.
Communication et résolution DNS
Première étape, la résolution DNS (Domain Name System). En effet, il est bien joli de vouloir contacter www.bases-hacking.org, mais l'ordinateur ne sait pas plus que vous où le trouver. Ceci nous ammène à considérer les fondements de l'Internet. Comment les ordinateurs communiquent-ils entre eux ?
On peut voir l'Internet comme une sorte de toile d'araignée géante (d'où le www, World Wide Web) constituée de noeuds que sont les routeurs et autres équipements télécom permettant la transmission des messages. Le schéma suivant donne une vision très schématique de ce qu'est l'Internet et permet d'envisager la façon dont peuvent communniquer différents acteurs.
Dans cet exemple, nous avons l'ordinateur A ayant par exemple comme fournisseur d'accès Orange et cherchant à joindre l'ordinateur B qui a deux connexions, l'une chez Free et l'autre chez Cogent. Tout d'abord, le message de A va devoir sortir de son réseau local (via un routeur ou autres modems ADSL). Une fois sorti, il se retrouve sur le réseau de son ISP (Internet Service Provider, Fournisseur d'Accès Internet ou FAI en français). Le message va être routé (ie, transporté) vers ceux que l'on dénomme les "points de peering", autrement dit de gros switchs où viennent s'interconnecter les ISP ainsi que certains professionels, notamment les hébergeurs. Le message passe donc dans le réseau de Free ou dans celui de Cogent pour arriver vers l'ordinateur B, en passant par les réseaux internes de l'ISP concerné, de la même façon qu'à l'aller.
Les messages transitants de cette façon utilisent un protocole de communication appellé IP (Internet Protocol), qui assigne à chaque noeud du réseau une "adresse" numérique composés de quatres octets (entre 0 et 255), bien connue sous le nom d'adresse IP. Ainsi, si tous les composants du réseau sont correctement configurés, ils vont tout simplement pouvoir faire transiter les paquets vers la cible correcte. Par exemple, on pourrait configuer un routeur en lui indiquant que tous les messages en direction de 1.2.3.4 doivent passer par Cogent, ceux qui sont de type 1.4.3.5 sont utilisés par Free, etc... Ces règles sont aussi appellées routes. Aller plus en profondeur sur les moyens de communication mis en oeuvre serait fort intéressant mais n'est pas notre but ici. Nous voulons simplement donner une idée grossière de la façon dont les communications s'effectuent.
Le dernier maillon de la chaîne est donc ce fameux DNS. En effet, il existe des registres permettant d'associer des noms de domaines (ici, bases-hacking.org) avec les adresses IP que nous venons d'évoquer. En réalité, l'ordinateur A va demander à son serveur DNS préféré l'adresse du nom demandé. Ce serveur intermédiaire va consulter ceux que l'on nomme les root servers, qui sont au nombre de 13 et constituent la base de l'Internet actuel. Ils vont consulter leur registres. S'ils ne connaissent pas le nom, ils vont rediriger vers un autre serveur DNS responsable de la zone en question (par exemple, les .org sont maintenus par les serveurs X.Y.Z.D et Z.E.R.D). Si ces nouveaux serveurs ne connaissent pas le nom, ils vont encore déléguer au serveur DNS responsable de la zone en question, etc, jusqu'à ce que le nom soit trouvé ou qu'un serveur n'ai ni le nom en base, ni un serveur auxiliaire responsable d'une zone liée au nom de domaine. Une fois cet enchaînement terminé, le serveur préféré va pouvoir retourner la réponse au demandeur, comme dans l'exemple qui suit :
-
$ nslookup bases-hacking.org
Server: 208.67.222.222
Address: 208.67.222.222#53
Non-authoritative answer:
Name: bases-hacking.org
Address: 213.186.33.87
$
Avec tout cela, notre navigateur a enfin déterminé qui nous souhaitons qu'il contacte. Puisque rien n'est superflu dans l'URL que nous avons entrée, c'est que ce http:// doit servir à quelquechose, non ? En effet, comme nous allons le voir tout de suite, ce préfixe indique le protocole, ou langage, qui va être utilisé entre nous et bases-hacking.org pour que chacun puisse comprendre les questions/réponses de l'autre.
De l'autre côté de la barrière se trouve donc le serveur Web (Apache, IIS, JBoss, GlassFish, etc...), ou serveur HTTP (HyperText Transfert Protocol). Le protocole HTTP est donc finalement le langage qui va permettre au client (le navigateur) de demander au serveur des ressources (par exemple, vous avez demandé ici au serveur la ressource fonctionnement-web.html). Ensuite, le serveur, connaissant la demande, est libre de chercher la ressource, en ajoutant des données dynamiques ou non et la renvoie via ce même protocole au client. On parle donc de requêtes (du navigateur) et de réponses (du serveur) HTTP. Requêtes et réponses sont toutes formées de la même façon : des en-têtes, ou headers décrivent la demande et fournissent des indications supplémentaires (permettant d'identifier le client, son navigateur, le type de langue qu'il sait lire ou encore des informations sur les données à suivre par exemple). Ensuite suivent les données à transmettre. Un petit aparté sur les headers HTTP et le protocole en général est fait dans un article annexe, ne nous attardons donc pas plus sur ce langage et revenons à notre serveur.
En effet, côté serveur, on est libre de faire les traitements internes nécessaires afin de rendre un résultat personnalisé à l'internaute. En réalité, les fichiers distants demandés peuvent être écrits avec n'importe quel langage de programmation (de façon plus commune, PHP, ASP, Java, PERL...). Le serveur va les analyser et les exécuter avant d'en renvoyer les résultat. Le serveur possède donc ou peut contacter diverses resources, bases de données ou programme d'interprétation qui vont garantir au client distant une navigation plus évoluée. Ainsi, une requête HTTP vers www.bases-hacking.org pourrait être schématisée de la manière suivante :
De son côté, le navigateur va recevoir les données et les mettre en forme de manière visuelle pour les rendre à l'utilisateur. De manière générale, le contenu Web est formatté selon le langage HTML (HyperText Markup Language). Par exemple, vous pouvez faire clic droit > Afficher la source pour voir le langage dans son plus simple appareil. Plusieurs types de contenus/langages (images, Java, JavaScript, Flash, etc...) peuvent être incorporés à ce HTML et seront analysés et affichés par le navigateur. Des parties de ces données peuvent également être stockées sur l'ordinateur de la personne qui consulte le site, afin d'enregistrer des profils de navigation ou un identifiant réutilisable pour une authentification ultérieur. Ce sont les cookies (article annexe).
Voici donc pour les basiques du fonctionnement de l'Internet et plus particulièrement de la navigation sur les sites Webs. Passons donc sans plus attendre à nos premières exploitation : les inclusions dynamiques.
| Inclusions dynamiques >> |
454 Commentaires
Afficher tous
| tresor | 12/05/14 16:09 |
| C'est vraiment génial. Merci! |
|
| Yokan | 29/04/14 13:50 |
| Ce site est vraiment parfait pour apprendre le hacking correctement, un vrai travail derrière tout ça. |
|
| dKious | 18/04/14 19:05 |
| Ok merci :-) |
|
| Anonyme | 17/04/14 09:31 |
| Bien merci |
|
Commentaires désactivés.
Apprendre la base du hacking - Liens sécurité informatique/hacking - Contact
Copyright © Bases-Hacking 2007-2014. All rights reserved.
Copyright © Bases-Hacking 2007-2014. All rights reserved.